Proper JSON and property bags
Posted: May 13, 2020 Filed under: Uncategorized 2 CommentsI recently wrote a blog post where I argued that “JSON serialization” as commonly practiced in the software industry is much too ambitious. This is the case at least in the .NET and Java ecosystems. I can’t really speak to the state of affairs in other ecosystems, although I note that the amount of human folly appears to be a universal constant much like gravity.
The problem is that so-called “JSON serializers” handle not just serialization and deserialization of JSON, they tend to support arbitrary mapping between the JSON model and some other data model as well. This additional mapping, I argued, causes much unnecessary complexity and pain. Whereas serialization and deserialization of JSON is a “closed” problem with bounded complexity, arbitrary mapping between data models is an “open” problem with unbounded complexity. Hence JSON serializers should focus on the former and let us handle the latter by hand.
I should add that there is nothing that forces developers to use the general data model mapping capabilities of JSON serializers of course. We’re free to use them in much more modest ways. And we should.
That’s all well and good. But what should we do in practice? There are many options open to us. In this blog post I’d like to explore a few. Perhaps we’ll learn something along the way.
Before we proceed though, we should separate cleanly between serialization and deserialization. When a software module uses JSON documents for persistence, it may very well do both. In many cases, however, a module will do one or the other. A producer of JSON documents only does serialization, a consumer only does deserialization. In general, the producer and consumer are separate software modules, perhaps written in different languages by different teams.
It looks like this:

There doesn’t have to be a bi-directional mapping between a single data model and JSON text. There could very well be two independent unidirectional mappings, one from a source model to JSON (serialization) and the other from JSON to a target model (deserialization). The source model and the target model don’t have to be the same. Why should they be? Creating a model that is a suitable source for serialization is a different problem from creating a model that is suitable target for deserialization. We are interested in suitable models for the task at hand. What I would like to explore, then, are some alternatives with respect to what the JSON serializer actually should consume during serialization (the source model) and produce during deserialization (the target model).
In my previous blog post I said that the best approach was to use “an explicit representation of the JSON data model” to act as an intermediate step. You might be concerned about the performance implications of the memory allocations involved in populating such a model. I am not, to be honest. Until I discover that those allocations are an unacceptable performance bottleneck in my application, I will optimize for legibility and changeability, not memory footprint.
But let’s examine closer what a suitable explicit representation could be. JSON objects are property bags. They have none of the ambitions of objects as envisioned in the bold notion of object-oriented programming put forward by Alan Kay. There is no encapsulation and definitely no message passing involved. They’re not alive. You can’t interact with them. They’re just data. That may be a flaw or a virtue depending on your perspective, but that’s the way it is. JSON objects are very simple things. A JSON object has keys that point to JSON values, which may be null, true, false, a number, a string, an array of JSON values, or another object. That’s it. So the question becomes: what is an appropriate representation for those property bags?
JSON serializers typically come with their own representation of the JSON data model. To the extent that it is public, this representation is an obvious possibility. But what about others?
I mentioned in my previous blog post that the amount of pain related to ambitious “JSON serializers” is proportional to the conceptual distance involved in the mapping, and also of the rate of change to that mapping. In other words, if the model you’re mapping to or from is significantly different from the JSON model, there will be pain. If the model changes often, there will be no end to the pain. It’s a bad combination. Conversely, if you have a model that is very close to the JSON model and that hardly ever changes, the amount of pain will be limited. We are still technically in the land of unbounded complexity, but if we are disciplined and staying completely still close to the border, it might not be so bad? A question might be: how close to the JSON model must we stay to stay out of trouble? Another might be: what would be good arguments to deviate from the JSON model?
When exploring these alternatives, I’ll strive to minimize the need for JSON serializer configuration. Ideally there should be no configuration at all, it should just work as expected out of the box. In my previous blog post I said that the black box must be kept closed lest the daemon break free and wreak havoc. Once we start configuring, we need to know the internal workings of the JSON serializer and the fight to control the daemon will never stop. Now your whole team needs to be experts in JSON serializer daemon control. Let’s make every effort to stay out of trouble and minimize the need for configuration. In other words, need for configuration counts very negatively in the evaluation of a candidate model.
Example: shopping-cart.json
To investigate our options, I’m going to need an example. I’m going to adapt the shopping cart example from Scott Wlaschin’s excellent book on domain modelling with F#.
A shopping cart can be in one of three states: empty, active or paid. How would we represent something like that as JSON documents?
First, an empty shopping cart.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "_state": "empty" | |
| } |
Second, an active shopping cart with two items in it, a gizmo and a widget. You’ll notice that items may have an optional description that we include when it’s present.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "_state": "active", | |
| "unpaidItems": [ | |
| { | |
| "id": "1bcd", | |
| "title": "gizmo" | |
| }, | |
| { | |
| "id" : "3cdf", | |
| "title": "widget", | |
| "description": "A very useful item" | |
| } | |
| ] | |
| } |
And finally, a paid shopping cart with two items in it, the amount and currency paid, and a timestamp for the transaction.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "_state": "paid", | |
| "paidItems": [ | |
| { | |
| "id": "1bcd", | |
| "title": "gizmo" | |
| }, | |
| { | |
| "id" : "3cdf", | |
| "title": "widget", | |
| "description": "A very useful item" | |
| } | |
| ], | |
| "payment": { | |
| "amount": 123.5, | |
| "currency": "USD" | |
| }, | |
| "timestamp": "2020-04-11T10:11:33.514+02:00" | |
| } |
You’ll notice that I’ve added a _state property to make it easier for a client to check which case they’re dealing with. This is known as a discriminator in OpenAPI, and can be used with the oneOf construct to create a composite schema for a JSON document.
So what are our options for explicit representations of these JSON documents in code?
We’ll take a look at the following:
- Explicit JSON model (Newtonsoft)
- Explicit DTO model
- Anonymous DTO model
- Dictionary
Explicit JSON model
Let’s start by using an explicit JSON model. An obvious possibility is to use the JSON model from whatever JSON serializer library we happen to be using. In this case, we’ll use the model offered by Newtonsoft.
We’ll look at serialization first. Here’s how we might create a paid cart as a JObject and use it to serialize to the appropriate JSON.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| var paidCartObject = new JObject( | |
| new JProperty("_state", new JValue("paid")), | |
| new JProperty("paidItems", | |
| new JArray( | |
| new JObject( | |
| new JProperty("id", new JValue("1bcd")), | |
| new JProperty("title", new JValue("gizmo"))), | |
| new JObject( | |
| new JProperty("id", new JValue("3cdf")), | |
| new JProperty("title", new JValue("widget")), | |
| new JProperty("description", new JValue("A very useful item"))))), | |
| new JProperty("payment", | |
| new JObject( | |
| new JProperty("amount", new JValue(123.5)), | |
| new JProperty("currency", new JValue("USD")))), | |
| new JProperty("timestamp", new JValue("2020-04-11T10:11:33.514+02:00"))); |
There’s no denying it: it is a bit verbose. At the same time, it’s very clear what we’re creating. We are making no assumptions that could be invalidated by future changes. We have full control over the JSON since we are constructing it by hand. We have no problems with optional properties.
What about deserialization?
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| var paidCartJsonString = @"{ | |
| ""_state"": ""paid"", | |
| ""paidItems"": [ | |
| { | |
| ""id"": ""1bcd"", | |
| ""title"": ""gizmo"" | |
| }, | |
| { | |
| ""id"" : ""3cdf"", | |
| ""title"": ""widget"", | |
| ""description"": ""A very useful item"" | |
| } | |
| ], | |
| ""payment"": { | |
| ""amount"": 123.5, | |
| ""currency"": ""USD"" | |
| }, | |
| ""timestamp"": ""2020-04-11T10:11:33.514+02:00"" | |
| }"; | |
| var paidCartDeserialized = JsonConvert.DeserializeObject(paidCartJsonText); | |
| var firstItemTitleToken = paidCartDeserialized["paidItems"][0]["title"]; | |
| var firstItemTitle = ((JValue) firstItemTitleToken).Value; | |
| var paymentCurrencyToken = paidCartDeserialized["payment"]["currency"]; | |
| var paymentCurrency = ((JValue) paymentCurrencyToken).Value; |
The deserialization itself is trivial, a one-liner. More importantly: there is no configuration involved, which is great news. Deserialization is often a one-liner, but you have to set up and configure the JSON serializer “just so” to get the output you want. Not so in this case. There are no hidden mechanisms and hence no surprises.
We can read data from the deserialized JObject by using indexers, which read pretty nicely. Unfortunately the last step is a little bit cumbersome, since we need to cast the JToken to a JValue before we can actually get to the value itself. Also, we obviously have to make sure that we get the property names right.
A drawback of using Newtonsoft’s JSON model is, of course, that we get locked-in to Newtonsoft. If we decide we want to try a hot new JSON serializer for whatever reason, we have to rewrite a bunch of pretty boring code. An alternative would be to create our own simple data model for JSON. But that approach has its issues too. Not only would we have to implement that data model, but we would probably have to teach our JSON serializer how to use it as a serialization source or deserialization target as well. A lot of work for questionable gain.
Explicit DTO model
Many readers of my previous blog post said they mitigated the pain of JSON serialization by using dedicated data transfer objects or DTOs as intermediaries between their domain model and any associated JSON documents. The implied cure for the pain, of course, is that the DTOs are much nearer to the JSON representation than the domain model is. The DTOs don’t have to concern themselves with things such as data integrity and business rules. The domain model will handle all those things. The domain model in turn doesn’t need to know that such a thing as JSON even exists. This gives us a separation of concerns, which is great.
However, the picture is actually a little bit more complex.
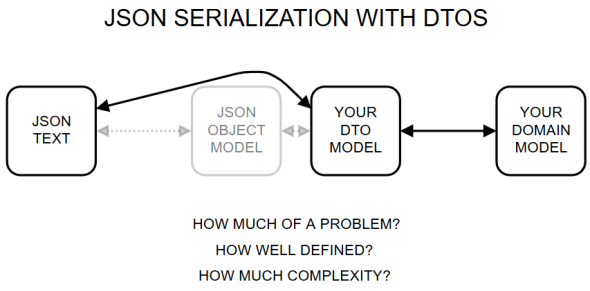
To keep the drawing simple, I’m pretending that there is a single DTO model and a bi-directional mapping between the DTO and the JSON. That doesn’t have to be the case. There might well be just a unidirectional mapping.
Even with a DTO, we have ventured into the land of unbounded complexity, on the tacit promise that we won’t go very far. The pain associated with JSON serialization will be proportional to the distance we travel. So let’s agree to stay within an inch of actual JSON. In fact, let’s just treat our explicit DTO model as named, static property bags.
To minimize pain, we’ll embrace some pretty tough restrictions on our DTOs. We’ll only allow properties of the following types: booleans, numbers (integers and doubles), strings, arrays, lists and objects that are themselves also DTOs. That might seem like a draconian set of restrictions, but it really just follows from the guideline that JSON serialization and deserialization should work out of the box, without configuration.
You’ll probably notice that there are no types representing dates or times in that list. The reason is that there are no such types in JSON. Dates and times in JSON are just strings. Ambitious JSON serializers will take a shot at serializing and deserializing types like DateTime for you of course, but the exact behavior varies between serializers. You’d have to know what your JSON serializer of choice happens to do, and you’d have to configure your JSON serializer to override the default behavior if you didn’t like it. That, to me, is venturing too far from the JSON model. I’ve seen many examples of developers being burned by automatic conversion of dates and times by JSON serializers.
Even with those restrictions, we still have many choices to make. In fact, it’s going to be a little difficult to achieve the results we want without breaking the no-configuration goal.
First we’re going to have to make some decisions about property names. In C#, the convention is to use PascalCase for properties, whereas our JSON documents use camelCase. This is a bit of a “when in Rome” issue, with the complicating matter that there are two Romes. There are two possible resolutions to this problem.
One option is to combine an assumption with an admission. That is, we can 1) make the assumption that our JSON documents only will contain “benign” property names that don’t contain whitespace or control characters and 2) accept that our DTOs will have property names that violate the sensitivies of a C# style checker. That will yield the following set of DTOs:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public abstract class ShoppingCart | |
| { | |
| public ShoppingCart(string state) | |
| { | |
| _state = state; | |
| } | |
| public string _state { get; } | |
| } | |
| public class EmptyCart : ShoppingCart | |
| { | |
| public EmptyCart() : base("empty") {} | |
| } | |
| public class ActiveCart : ShoppingCart | |
| { | |
| public ActiveCart() : base("active") { } | |
| public Item[] unpaidItems { get; set; } | |
| } | |
| public class PaidCart : ShoppingCart | |
| { | |
| public PaidCart() : base("paid") {} | |
| public object[] paidItems { get; set; } | |
| public Money payment { get; set; } | |
| public string timestamp { get; set; } | |
| } | |
| public class Item | |
| { | |
| public string id { get; set; } | |
| public string title { get; set; } | |
| public string description { get; set; } | |
| } | |
| public class Money | |
| { | |
| public float amount { get; set; } | |
| public string currency { get; set; } | |
| } |
Depending on your sensitivies, you may have run away screaming at this point. A benefit however, is that it works reasonably well out of the box. The property names in the DTOs and in the JSON are identical, which makes sense since the DTOs are a representation of the same property bags we find in the JSON. In this scenario, coupling of names is actually a good thing.
Another option is to add custom attributes to the properties of our DTOs. Custom attributes are a mechanism that some JSON serializers employ to let us create an explicit mapping between property names in our data model and property names in the JSON document. This clearly is a violation of the no-configuration rule, though. Do it at your own peril.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| abstract class ShoppingCart | |
| { | |
| public ShoppingCart(string state) | |
| { | |
| State = state; | |
| } | |
| [JsonProperty("_state")] | |
| public string State { get; } | |
| } | |
| class EmptyCart : ShoppingCart | |
| { | |
| public EmptyCart() : base("empty") {} | |
| } | |
| class ActiveCart : ShoppingCart | |
| { | |
| public ActiveCart() : base("paid") { } | |
| [JsonProperty("unpaidItems")] | |
| public Item[] UnpaidItems { get; set; } | |
| } | |
| class PaidCart : ShoppingCart | |
| { | |
| public PaidCart() : base("paid") {} | |
| [JsonProperty("paidItems")] | |
| public Item[] PaidItems { get; set; } | |
| [JsonProperty("payment")] | |
| public Money Payment { get; set; } | |
| [JsonProperty("timestamp")] | |
| public string Timestamp { get; set; } | |
| } | |
| class Item | |
| { | |
| [JsonProperty("id")] | |
| public string Id { get; set; } | |
| [JsonProperty("title")] | |
| public string Title { get; set; } | |
| [JsonProperty("description", NullValueHandling = NullValueHandling.Ignore)] | |
| public string Description { get; set; } | |
| } | |
| class Money | |
| { | |
| [JsonProperty("amount")] | |
| public double Amount { get; set; } | |
| [JsonProperty("currency")] | |
| public string Currency { get; set; } | |
| } |
This yields perhaps more conventional-looking DTOs. They are, however, now littered with custom attributes specific to the JSON serializer I’m using. There’s really a lot of configuration going on: every property is being reconfigured to use a different name.
We also have the slightly strange situation where the property names for the DTOs don’t really matter. It is a decoupling of sorts, but it doesn’t really do much work for us, seeing as the whole purpose of the DTO is to represent the data being transferred.
But ok. Let’s look at how our DTOs hold up as source models for serialization and target models for deserialization, respectively.
Here’s how you would create an instance of DTO v1 and serialize it to JSON.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| var paidCartDto1 = new PaidCart | |
| { | |
| paidItems = new Item[] { | |
| new Item { | |
| id = "1bcd", | |
| title = "gizmo" | |
| }, | |
| new Item { | |
| id = "3cdf", | |
| title = "widget", | |
| description = "A very useful item" | |
| } | |
| }, | |
| payment = new Money { | |
| mount = 123.5, | |
| currency = "USD" | |
| }, | |
| timestamp = "2020-04-11T10:11:33.514+02:00" | |
| }; | |
| var paidCartDto1JsonText = JsonConvert.SerializeObject(paidCartDto1); |
It’s pretty succinct and legible, and arguably looks quite similar to the JSON text it serializes to. However, there is a small caveat: our optional description is included with a null value in the JSON. That’s not really what we aimed for. To change that behaviour, we can configure our JSON serializer to omit properties with null values from the serialized output. But now we have two problems. The first is that we had to resort to configuration, the second is that we’ve placed a bet: that all properties with null values should always be omitted from the output. That’s the case today, but it could definitely change. To gain more fine-grained control, we’d have to dig out more granular and intrusive configuration options, like custom attributes or custom serializers. Or perhaps some combination? That’s even worse, now our configuration is spread over multiple locations – who knows what the aggregated behavior is and why?
What about DTO v2? The code looks very similar, except it follows C# property naming standards and at the same time deviates a little bit from the property names that we actually find in the JSON document. We’d have to look at the definition of the PaidCart to convince ourselves that it probably will serialize to the appropriate JSON text, since we find the JSON property names there – not at the place we’re creating our DTO.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| var paidCartDto2 = new PaidCart | |
| { | |
| PaidItems = new Item[] { | |
| new Item { | |
| Id = "1bcd", | |
| Title = "gizmo" | |
| }, | |
| new Item { | |
| Id = "3cdf", | |
| Title = "widget", | |
| Description = "A very useful item" | |
| } | |
| }, | |
| Payment = new Money { | |
| Mount = 123.5, | |
| Currency = "USD" | |
| }, | |
| Timestamp = "2020-04-11T10:11:33.514+02:00" | |
| }; | |
| var paidCartDto2JsonText = JsonConvert.SerializeObject(paidCartDto2); |
A benefit is that since we already littered the DTO with custom attributes, I made sure to add a NullValueHandling.Ignore to the Description property, so that the property is not included in the JSON if the value is null. Of course I had to Google how to do it, since I can’t ever remember all the configuration options and how they fit together.
So that’s serialization. We can get it working, but it’s obvious that the loss of control compared to using the explicit JSON model is pushing us towards making assumptions and having to rely on configuration to tweak the JSON output. We’ve started pushing buttons and levers. The daemon is banging against walls of the black box.
What about deserialization? Here’s how it looks for a paid cart using DTO v2:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| var paidCartJsonString = @"{ | |
| ""_state"": ""paid"", | |
| ""paidItems"": [ | |
| { | |
| ""id"": ""1bcd"", | |
| ""title"": ""gizmo"" | |
| }, | |
| { | |
| ""id"" : ""3cdf"", | |
| ""title"": ""widget"", | |
| ""description"": ""A very useful item"" | |
| } | |
| ], | |
| ""payment"": { | |
| ""amount"": 123.5, | |
| ""currency"": ""USD"" | |
| }, | |
| ""timestamp"": ""2020-04-11T10:11:33.514+02:00"" | |
| }"; | |
| var paidCartDtoFromText = JsonConvert.DeserializeObject<PaidCart>(paidCartJsonString); | |
| var firstItemTitle = paidCartDtoFromText.PaidItems[0].Title; | |
| var currency = paidCartDtoFromText.Payment.Currency; |
Well, what can I say. It’s quite easy if we know in advance if we’re dealing with an empty cart, an active cart or a paid cart! And it’s very easy and access the various property values.
But of course we generally don’t know what kind of shopping the JSON document describes. That information is in the JSON document!
What we would like to write in our code is something like this:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| var shoppingCartDtoFromText = JsonConvert.DeserializeObject<ShoppingCart>(jsonText); |
But the poor JSON serializer can’t do that, not without help! The problem is that the JSON serializer doesn’t know which subclass of ShoppingCart to instantiate. In fact, it doesn’t even know that the subclasses exist.
We have three choices at this point. First, we can create a third variation of our DTO, one that doesn’t have this problem. We could just the collapse our fancy class hierarchy and use something like this:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| class ShoppingCart | |
| { | |
| [JsonProperty("_state")] | |
| public string State { get; set; } | |
| [JsonProperty("unpaidItems", NullValueHandling = NullValueHandling.Ignore)] | |
| public Item[] UnpaidItems { get; set; } | |
| [JsonProperty("paidItems", NullValueHandling = NullValueHandling.Ignore)] | |
| public Item[] PaidItems { get; set; } | |
| [JsonProperty("payment", NullValueHandling = NullValueHandling.Ignore)] | |
| public Money Payment { get; set; } | |
| [JsonProperty("timestamp", NullValueHandling = NullValueHandling.Ignore)] | |
| public string Timestamp { get; set; } | |
| } |
It’s not ideal, to put it mildly. I think we can probably agree that this is not a good DTO, as it completely muddles together what was clearly three distinct kinds of JSON documents. We’ve lost that now, in an effort to make the JSON deserialization process easier.
The second option is to pull out the big guns and write a custom deserializer. That way we can sneak a peek at the _state property in the JSON document, and based on that create the appropriate object instance. To manage that requires, needless to say, a fair bit of knowledge of the workings of our JSON serializer. Chances are your custom deserializer will be buggy. If the JSON document format and hence the DTOs are subject to change (as typically happens), changes are it will stay buggy over time.
The third option is to protest against the design of the JSON documents! That would mean that we’re letting our problems with deserialization dictate our communication with another software module and potentially a different team of developers. It is not the best of reasons for choosing a design, I think. After all, there are alternative target models for deserialization that don’t have these problems. Why can’t we use one of them? But we might still be able to pull it off, if we really want to. It depends on our relationship with the owners of the supplier of the JSON document. It is now a socio-technical issue that involves politics and power dynamics between organizations (or different parts of the same organization): do we have enough leverage with the supplier of the JSON document to make them change their design to facilitate deserialization at our end? To we want to exercise that leverage? What are the consequences?
It’s worth noting that these problems only apply to DTOs as target models for deserialization. As source models for serialization, we can use our previous two variations, with the caveats mentioned earlier.
To conclude then, explicit DTOs are relatively straightforward as source models for serialization, potentially less so as target models for deserialization. A general drawback of using explicit DTOs is that we must write, maintain and configure a bunch of classes. That should be offset by some real, tangible advantage. Is it?
Anonymous classes
We can avoid the chore of having to write and maintain such classes by using anonymous classes in C# as DTOs instead. It might not be as silly as it sounds, at least for simple use cases.
For the serialization case, it would look something like this:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| var paidCartAnon = new | |
| { | |
| _state = "paid", | |
| paidItems = new object[] { | |
| new { | |
| id = "1bcd", | |
| title = "gizmo" | |
| }, | |
| new { | |
| id = "3cdf", | |
| title = "widget", | |
| description = "A very useful item" | |
| } | |
| }, | |
| payment = new { | |
| mount = 123.5, | |
| currency = "USD" | |
| }, | |
| timestamp = "2020-04-11T10:11:33.514+02:00" | |
| }; | |
| var paidCartAnonJsonText = JsonConvert.SerializeObject(paidCartAnon); |
This is actually very clean! The code looks really similar to the target JSON output. You may notice that the paidItems array is typed as object. This is to allow for the optional description of items. The two items are actually instances of distinct anonymous classes generated by the compiler. One is a DTO with two properties, the other a DTO with three properties. For the compiler, the two DTOs have no more in common than the fact that they are both objects.
As long as we’re fine with betting that the property names of the target JSON output will never contain whitespace or control characters, this isn’t actually a bad choice. No configuration is necessary to handle the optional field appropriately.
A short-coming compared to explicit DTOs is ease of composition and reuse across multiple DTOs. That’s not an issue in the simple shopping cart example, but it is likely that you will encounter it in a real-world scenario. Presumably you will have smaller DTOs that are building blocks for multiple larger DTOs. That might be more cumbersome to do using anonymous DTOs.
What about deserialization? Surely it doesn’t make sense to use an anonymous type as target model for deserialization? Newtonsoft thinks otherwise! Ambitious JSON serializers indeed!
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| var paidCartJsonString = @"{ | |
| ""_state"": ""paid"", | |
| ""paidItems"": [ | |
| { | |
| ""id"": ""1bcd"", | |
| ""title"": ""gizmo"" | |
| }, | |
| { | |
| ""id"" : ""3cdf"", | |
| ""title"": ""widget"", | |
| ""description"": ""A very useful item"" | |
| } | |
| ], | |
| ""payment"": { | |
| ""amount"": 123.5, | |
| ""currency"": ""USD"" | |
| }, | |
| ""timestamp"": ""2020-04-11T10:11:33.514+02:00"" | |
| }"; | |
| var anonymousPaidCartObject = JsonConvert.DeserializeAnonymousType(paidCartJsonString, | |
| new | |
| { | |
| _state = default(string), | |
| paidItems = new [] { | |
| new { | |
| id = default(string), | |
| title = default(string), | |
| description = default(string) | |
| } | |
| }, | |
| payment = new | |
| { | |
| amount = default(double), | |
| currency = default(string) | |
| }, | |
| timestamp = default(string) | |
| }); | |
| var firstItemTitle = anonymousPaidCartObject.paidItems[0].title; | |
| var currency = anonymousPaidCartObject.payment.currency; |
This actually works, but it’s a terrible idea, I hope you’ll agree. Creating a throw-away instance of an anonymous type in order to be able to reflect over the type definition is not how you declare types. It’s convoluted and confusing.
So while it is technically possible to use anonymous DTOs as target models for deserialization, you really shouldn’t. As source models for serialization, however, anonymous DTOs are not too bad. In fact, they have some advantages over explicit DTOs in that you don’t have to write and maintain them yourself.
Dictionary
Finally, we come to the venerable old dictionary! With respect to representing a property bag, it really is an obvious choice, isn’t it? A property bag is literally what a dictionary is. In particular, it should be a dictionary that uses strings for keys and objects for values.
Here is a dictionary used as serialization source:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| var paidCartBag = new Dictionary<string, object> { | |
| { | |
| "_state", "paid" | |
| }, | |
| { | |
| "paidItems", | |
| new List<object>() { | |
| new Dictionary<string, object> { | |
| { "id", "1bcd" }, | |
| { "title", "gizmo" } | |
| }, | |
| new Dictionary<string, object> { | |
| { "id", "3cdf" }, | |
| { "title", "widget" }, | |
| { "description", "A very useful item" } | |
| } | |
| } | |
| }, | |
| { | |
| "payment", | |
| new Dictionary<string, object> { | |
| { "amount", 123.5 }, | |
| { "currency", "USD" } | |
| } | |
| }, | |
| { | |
| "timestamp", "2020-04-11T10:11:33.514+02:00" | |
| } | |
| }; |
It is more verbose than the versions using explicit or anonymous DTOs above. I’m using the dictionary initializer syntax in C# to make it as compact as possible, but still.
It is very straightforward however. It makes no assumptions and places no bets against future changes to the JSON document format. Someone could decide to rename the paidItems property in the JSON to paid items and we wouldn’t break a sweat. The code change would be trivial. Moreover the effect of the code change would obviously be local – there would be no surprise changes to the serialization of other properties.
What about the deserialization target scenario, which caused so much trouble for our DTOs? We would like to be able to write something like this:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| var paidCartJsonString = @"{ | |
| ""_state"": ""paid"", | |
| ""paidItems"": [ | |
| { | |
| ""id"": ""1bcd"", | |
| ""title"": ""gizmo"" | |
| }, | |
| { | |
| ""id"" : ""3cdf"", | |
| ""title"": ""widget"", | |
| ""description"": ""A very useful item"" | |
| } | |
| ], | |
| ""payment"": { | |
| ""amount"": 123.5, | |
| ""currency"": ""USD"" | |
| }, | |
| ""timestamp"": ""2020-04-11T10:11:33.514+02:00"" | |
| }"; | |
| var paidCartBagFromText = JsonConvert.DeserializeObject<Dictionary<string, object>>(paidCartJsonString); | |
| var firstItemTitle = paidCartBagFromText["paidItems"][0]["title"]; | |
| var currency = paidCartBagFromText["payment"]["currency"]; |
Alas, it doesn’t work! The reason is that while we can easily tell the JSON serializer that we want the outermost object to be a dictionary, it doesn’t know that we want that rule to apply recursively. In general, the JSON serializer doesn’t know what to do with JSON objects and JSON arrays, so it must revert to defaults.
We’re back to custom deserializers, in fact. Deserialization really is much more iffy than serialization. The only good news is that deserialization of JSON into a nested structure of string-to-object dictionaries, object lists and primitive values is again a closed problem. It is not subject to change. We could do it once, and not have to revisit it again. Since our target model won’t change, our custom deserializer won’t have to change either. So while it’s painful, the pain is at least bounded.
Here is a naive attempt at an implementation, thrown together in maybe half an hour:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public class PropertyBagDeserializer : JsonConverter | |
| { | |
| public override bool CanRead => true; | |
| public override bool CanWrite => false; | |
| public override bool CanConvert(Type objectType) | |
| { | |
| return true; | |
| } | |
| public override object ReadJson(JsonReader reader, Type objectType, object existingValue, JsonSerializer serializer) | |
| { | |
| return ReadValue(reader, serializer); | |
| } | |
| private static object ReadValue(JsonReader reader, JsonSerializer serializer) | |
| { | |
| if (reader.TokenType == JsonToken.StartObject) | |
| { | |
| return ReadObjectValue(reader, serializer); | |
| } | |
| else if (reader.TokenType == JsonToken.StartArray) | |
| { | |
| return ReadArrayValue(reader, serializer); | |
| } | |
| else | |
| { | |
| return ReadSimpleValue(reader, serializer); | |
| } | |
| } | |
| private static object ReadObjectValue(JsonReader reader, JsonSerializer serializer) | |
| { | |
| reader.Read(); | |
| var dictionary = new Dictionary<string, object>(); | |
| while (reader.TokenType != JsonToken.EndObject) | |
| { | |
| if (reader.TokenType == JsonToken.PropertyName) | |
| { | |
| var propertyName = (string) reader.Value; | |
| reader.Read(); | |
| dictionary[propertyName] = ReadValue(reader, serializer); | |
| } | |
| } | |
| reader.Read(); | |
| return dictionary; | |
| } | |
| private static object ReadArrayValue(JsonReader reader, JsonSerializer serializer) | |
| { | |
| reader.Read(); | |
| var list = new List<object>(); | |
| while (reader.TokenType != JsonToken.EndArray) | |
| { | |
| list.Add(ReadValue(reader, serializer)); | |
| } | |
| reader.Read(); | |
| return list; | |
| } | |
| private static object ReadSimpleValue(JsonReader reader, JsonSerializer serializer) | |
| { | |
| var val = serializer.Deserialize(reader); | |
| reader.Read(); | |
| return val; | |
| } | |
| public override void WriteJson(JsonWriter writer, object value, JsonSerializer serializer) | |
| { | |
| throw new NotImplementedException(); | |
| } | |
| } |
It probably has bugs. It didn’t crash on my one test input (the paid cart JSON we’ve seen multiple times in this blog post), that’s all the verification I have done. Writing custom deserializers is a pain, and few developers have enough time available to become experts at it. I’m certainly no expert, I have to look it up and go through a slow discovery process every time. But there is a chance that it might one day become relatively bug-free, since the target isn’t moving. There are no external sources of trouble.
With the custom deserializer, deserializing to a dictionary looks like this:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| var paidCartJsonString = @"{ | |
| ""_state"": ""paid"", | |
| ""paidItems"": [ | |
| { | |
| ""id"": ""1bcd"", | |
| ""title"": ""gizmo"" | |
| }, | |
| { | |
| ""id"" : ""3cdf"", | |
| ""title"": ""widget"", | |
| ""description"": ""A very useful item"" | |
| } | |
| ], | |
| ""payment"": { | |
| ""amount"": 123.5, | |
| ""currency"": ""USD"" | |
| }, | |
| ""timestamp"": ""2020-04-11T10:11:33.514+02:00"" | |
| }"; | |
| var paidCartBagFromText = JsonConvert.DeserializeObject<Dictionary<string, object>>(paidCartJsonString); | |
| var paidItems = (List<object>) paidCartBagFromText["paidItems"]; | |
| var firstItem = (Dictionary<string, object>) paidItems[0]; | |
| var firstItemTitle = (string) firstItem["title"]; | |
| var payment = (Dictionary<string, object>) paidCartBagFromText["payment"]; | |
| var currency = (string) payment["currency"]; |
There is a lot of casting going on. We might be able to gloss it over a bit by offering some extension methods on dictionary and list. I’m not sure it would help or make matters worse.
The reason is in JSON’s nature, I guess. It is a completely heterogenic property bag. It’s never going to be a frictionless thing in a statically typed language, at least not of the C# ilk.
Summary
What did we learn? Did we learn anything?
Well, we learned that deserialization in general is much more bothersome than serialization. Perhaps we already suspected as much, but it really became painfully clear, I think. In fact, the only target model that will let us do deserialization without either extensive configuration, making bets against the future or potentially engaging in organizational tug of war is the explicit JSON model. But luckily that’s actually a very clean model as well. The explicit JSON model is verbose when you use it to create instances by hand. But we’re not doing that. The JSON serializer does all of that, and it does it robustly because it’s the JSON serializer’s own model. Reading values out of the JSON model is actually quite succinct and nice. And when we’re deserializing, we’re only reading. I therefore recommend using that model as target model for deserialization.
For serialization, there is more competition and hence the conclusion is less clear-cut. The explicit JSON model is still a good choice, but it is pretty verbose. You might prefer to use a dictionary or some sort of DTO, either explicit or anonymous. However, both of the latter come with some caveats and pitfalls. I think actually the good old dictionary might be the best choice as source model for serialization.
What do you think?

Typo in line 18 for ActiveCart constructor ? should be base(“active”) ??
Yes, thanks, well spotted! I’ve updated the gist.